高性能的 Linux 集群介绍
这两篇系列文章简要介绍采用 Linux 集群技术的高性能计算(HPC)的概念,展示如何构建集群并编写并行程序。本文是两篇系列文章中的第一篇,讨论了集群的类型、用途、HPC 基础、Linux 在 HPC 中的角色以及集群技术日益增长的原因。第 2 部分将介绍并行算法的知识,并介绍如何编写并行程序、如何构建集群以及如何进行基准测试。
HPC 体系架构的类型
大部分 HPC 系统都使用了并行 的概念。有很多软件平台都是面向 HPC 的,但是首先让我们先来了解一下硬件的知识。
HPC 硬件可以分为 3 类:
- 对称多处理器(SMP)
- 向量处理器
- 集群
对称多处理器(SMP)
SMP 是 HPC 采用的体系架构之一,其中有多个处理器会共享内存。(在集群中,这也称为 大规模并行处理器(massively parallel processor,MPP),它们并不需要共享内存;稍后我们将更详细介绍这方面的内容。)与 MPP 相比,SMP 通常成本更高,而且可伸缩性较差。
向量处理器
顾名思义,在向量处理器中,CPU 被优化以便很好地处理向量数组的运算。向量处理器系统的性能很高,在 20 世纪 80 年代到 90 年代早期一度在 HPC 体系架构中占有统治地位,但是最近几年以来,集群变得更加流行了。
集群
集群是最近几年中最为主要的一种 HPC 硬件:集群(cluster) 就是一组 MPP 的集合。集群中的处理器通常被称为 节点,它具有自己的 CPU、内存、操作系统、I/O 子系统,并且可以与其他节点进行通信。目前有很多地方都使用常见的工作站运行 Linux 和其他开放源码软件来充当集群中的节点。
接下来您将看到这些 HPC 硬件之间的区别,但是首先让我们从集群开始。
集群定义
术语“集群(cluster)”在不同的地方可能会意味着不同的意义。本文重点介绍以下三种类型的集群:
- 故障迁移集群
- 负载均衡集群
- 高性能集群
故障迁移集群
最简单的故障迁移集群有两个节点:一个节点是活动的,另外一个节点是备用的,不过它会一直对活动节点进行监视。一旦活动节点出现故障,备用节点就会接管它的工作,这样就能使得关键的系统能够持续工作。
负载均衡集群
负载均衡集群通常会在非常繁忙的 Web 站点上采用,它们有多个节点来承担相同站点的工作,每个获取 Web 页面的新请求都被动态路由到一个负载较低的节点上。
高性能集群
高性能集群用来运行那些对时间敏感的并行程序,它们对于科学社区来说具有特殊的意义。高性能集群通常会运行一些模拟程序和其他对 CPU 非常敏感的程序,这些程序在普通的硬件上运行需要花费大量的时间。
图 1 解释了一个基本的集群。本系列文章的第 2 部分将展示如何创建这种集群,并为其编写程序。
图 1. 基本的集群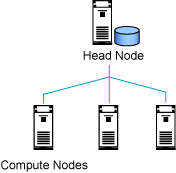
网格计算 是一个更为广泛的术语,通常用来代表利用松耦合系统之间的协作来实现面向服务的架构(SOA)。基于集群的 HPC 是网格计算的一个特例,其中节点之间都是紧耦合的。网格计算的一个成功的、众所周知的项目是 SETI@home,即搜索外星智慧的项目,它使用了大约一百万台家用 PC 在屏保时的空闲 CPU 周期来分析无线电天文望远镜的数据。另外一个类似的成功项目是 Folding@Home 项目,用来进行蛋白质的折叠计算。
高性能集群的常见用途
几乎所有的产业界都需要快速的处理能力。随着越来越便宜而且快速的计算机的出现,更多公司表现出了对利用这些技术优势的兴趣。人们对于计算处理能力的需求是没有上限的;尽管处理能力在迅速提高,但是人们的需求仍然超出计算能力所能提供的范围。
生命科学研究
蛋白质分子是非常复杂的链,实际上可以表示为无数个 3D 图形。实际上,在将蛋白质放到某种溶液中时,它们会快速“折叠”成自己的自然状态。不正确的折叠会导致很多疾病,例如 Alzheimer 病;因此,对于蛋白质折叠的研究非常重要。
科学家试图理解蛋白质折叠的一种方式是通过在计算机上进行模拟。实际上,蛋白质的折叠进行得非常迅速(可能只需要 1 微秒),不过这个过程却非常复杂,这个模拟在普通的计算机上可能需要运行 10 年。这个领域只不过是诸多业界领域中很小的一个,但是它却需要非常强大的计算能力。
业界中其他领域包括制药建模、虚拟外科手术训练、环境和诊断虚拟化、完整的医疗记录数据库以及人类基因项目。
石油和天然气勘探
震动图中包含有大陆和洋底内部特性的详细信息,对这些数据进行分析可以帮助我们探测石油和其他资源。即便对于一个很小的区域来说,也有数以 TB 计的数据需要重构;这种分析显然需要大量的计算能力。这个领域对于计算能力的需求是如此旺盛,以至于超级计算机大部分都是在处理这种工作。
其他地理学方面的研究也需要类似的计算能力,例如用来预测地震的系统,用于安全性工作的多谱段卫星成像系统。
图像呈现
在工程领域(例如航天引擎设计)操纵高分辨率的交互式图像在性能和可伸缩性方面历来都是一种挑战,因为这要涉及大量的数据。基于集群的技术在这些领域已经取得了成功,它们将渲染屏幕的任务分割到集群中的各个节点上,在每个节点上都利用自己的图形硬件来呈现自己这部分屏幕的图像,并将这些像素信息传送到一个主节点上,主节点对这些信息进行组合,最终形成一个完整的图像。
这个领域中的例子目前才不过是冰山一角;更多的应用程序,包括天体物理模拟、气象模拟、工程设计、金融建模、证券模拟以及电影特技,都需要丰富的计算资源。对于计算能力越来越多的需求我们就不再进行介绍了。
Linux 和集群如何改变了 HPC
在基于集群的计算技术出现之前,典型的超级计算机都是向量处理器,由于它们全部采用专用的硬件和软件,因此成本通常会超过一百万美元。
随着 Linux 和其他免费的集群开放源码软件组件的出现和常用硬件处理能力的提高,这种情况现在已经发生了很大的变化。您可以利用少量的成本来构建功能强大的集群,并能够根据需要来添加其他节点。
GNU/Linux 操作系统(Linux)已经在集群中得到了大量的采用。Linux 可以在很多硬件上运行,并且具有高质量的编译器和其他软件,例如并行文件系统和 MPI 实现在 Linux 上都是免费的。采用 Linux,用户还可以针对自己的任务负载对内核进行定制。Linux 是构建 HPC 集群的一个非常好的平台。
理解硬件:向量机与集群
要理解 HPC 硬件,对向量计算和集群计算进行一下比较是非常有用的。二者是互相竞争的技术(地球模拟器 是一台向量超级计算机,目前仍然是最快的 10 台机器之一)。
从根本上来讲,向量处理器和标量处理器都是基于时钟周期来执行指令的;使它们产生区别的是向量处理器并行处理与向量有关的计算的能力(例如矩阵乘法),这在高性能计算中是非常常见的。为了展示这一点,假设您有两个双精度的数组 a 和 b,并且要创建第三个数组 x,比如 x[i]=a[i]+b[i]。
任何浮点操作,例如加法和乘法,都可以通过几个步骤来实现:
- 进行指数调整
- 添加符号
- 对结果进行取整检查等
向量处理器通过使用 流水线(pipeline) 技术在内部对这些步骤进行并行处理。假设在一个浮点加法运算中有六个步骤(与 IEEE 算术硬件一样),如图 2 所示:
图 2. IEEE 算术硬件中的六级流水线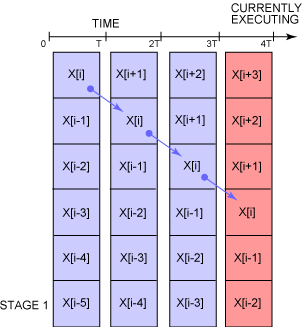
向量处理器可以并行处理这六个步骤 —— 如果第 i 个数组元素是在第 4 个步骤中被添加的,那么向量处理器就会为第 (i+1) 个元素执行第 3 个步骤,为第 (i+2) 个元素执行第 2 个步骤,依此类推。正如您可以看到的一样,对于一个 6 级的浮点加运算来说,加速比非常接近于 6(在开始和结束时,这六个步骤并不是都处于活动状态的),因为在任何给定的时刻(图 2 所示的红色),这些步骤都是活动的。这样做的一大优点是并行处理都是在幕后进行的,您并不需要在程序中显式地进行编码。
对于大部分情况来说,这六个步骤都可以并行执行,这样就可以获得几乎 6 倍的性能提高。箭头表示了对第 i 个数组元素所进行的操作。
与向量处理相比,基于集群的计算采用的是完全不同的一种方法。它不使用专门优化过的向量硬件,而是使用标准的标量处理器,但是它采用了大量的处理器来并行处理多个计算任务。
集群的特性如下:
- 集群都是使用常见的硬件进行构建的,其成本只是向量处理器的很小一部分。在很多情况中,价格会低一个数量级以上。
- 集群使用消息传递系统进行通信,程序必须显式地进行编码来使用分布式硬件。
- 采用集群,您可以根据需要向集群中添加节点。
- 开放源码软件组件和 Linux 降低了软件的成本。
- 集群的维护成本很低(它们占用的空间较小,耗费的电力较少,对于制冷条件的需求较低)。
并行编程和 Amdahl 法则
当在集群上实现高性能环境时,软件和硬件就需要联合起来工作。程序在编写时必须要显式地利用底层硬件的优点,如果现有的非并行程序不能很好地在集群上运行,那么这些程序必须重新进行编写。
并行程序一次要执行很多操作。其数量取决于目前正在解决的问题。假设一个程序所花费的时间中有 1/N 是不能并行处理的,那么剩余的 (1-1/N) 就是可以并行处理的部分(请参看图 3)。
图 3. Amdahl 法则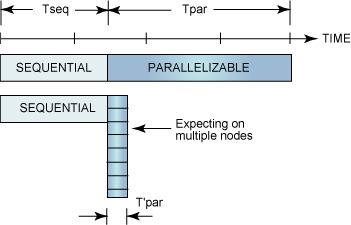
从理论上来说,您可以采用无数的硬件来处理并行执行的部分,甚至在接近 0 的时间内完成这些任务,但是对于串行部分来说,这样做不会有任何提高。结果是,可以实现的最佳结果是使用原来的 1/N 的时间来执行整个程序,但是不可能再快了。在并行编程中,这个事实通常就称为 Amdahl 法则。
Amdahl 法则揭示了使用并行处理器来解决问题与只使用一个串行处理器来解决问题的加速比。加速比(speedup) 的定义如下:(使用多个处理器)并行执行程序所需要的时间除以(使用一个处理器)串行执行程序所需要的时间:
T(1)S = ------ T(j) |
其中 T(j) 是在使用 j 个处理器来执行程序时所需要的时间。
在图 3 中,如果采用足够多的节点来进行并行处理,那么 T'par 就可以非常接近于 0,但是 Tseq 却不会变化。在最好的情况中,并行程序也不可能快到原来的 1+Tpar/Tseq。
在编写并行程序时真正困难的事情是使 N 尽量大。但是这件事情却有两面性。通常都是要试图在更为强大的计算机上来解决更大的问题,通常随着所解决问题的规模的增大(例如试图修改程序并提高可并行的部分来优化地利用可用资源),所花费在串行部分上的时间就会减少。因此,N 值就会自动变大了。
现在让我们介绍两种并行编程的方法:分布式内存方法 和 共享式内存方法。
此处我们考虑一种主从模式非常有用:
- 主节点负责将任务划分到多个从节点上。
- 从节点负责处理自己所接收到的任务。
- 如果需要,从节点之间会相互进行通信。
- 从节点将结果返回给主节点。
- 主节点收集结果,并继续分发任务,依此类推。
显然,这种方法的问题就产生于分布式内存的组织。由于每个节点都只能访问自己的内存,如果其他节点需要访问这些内存中的数据,就必须对这些数据结构进行复制并通过网络进行传送,这会导致大量的网络负载。要编写有效的分布式内存的程序,就必须牢记这个缺点和主从模型。
在共享式内存方法中,内存对于所有的处理器(例如 SMP)来说都是通用的。这种方法并没有分布式内存方法中所提到的那些问题。而且对于这种系统进行编程要简单很多,因为所有的数据对于所有的处理器来说都是可以使用的,这与串行程序并没有太多区别。这些系统的一个大问题是可伸缩能力:不容易添加其他处理器。
并行编程(与所有的编程技术一样)与其他科学一样,都是一门艺术,总会留下一定的空间来进行设计的改进和性能的提高。并行编程在计算中有自己特殊的地位:本系列文章的第 2 部分将介绍并行编程平台,并给出几个例子。
有些应用程序通常会需要从磁盘中读写大量的数据,这通常是整个计算过程中速度最慢的一个步骤。更快的硬盘驱动器能够帮助解决一些问题,但是有时这是不够的。
如果一个物理磁盘分区是在所有节点之间共享的(例如使用 NFS),就像是在 Linux 集群中经常采用的方法一样,那么这个问题就会变得更加明显了。此时就是并行文件系统的用武之地了。
并行文件系统(Parallel filesystem) 将数据存放在分布在多个磁盘上的文件中,这些磁盘连接到集群中的多个节点上,这些节点称为 I/O 节点。当一个程序试图读取某个文件时,可以并行地从多块磁盘上分别读取这个文件的某些部分。这可以降低某个磁盘控制器上的负载,并能够处理更多请求。(PVFS 就是一个很好的开放源码并行文件系统;目前已经在 Linux 集群上使用标准的 IDE 硬盘实现了超过 1 GB/s 的磁盘性能。)
PVFS 可以作为一个 Linux 内核模块使用,也可以编译到 Linux 内核中。底层的概念非常简单(请参看图 4):
- 元数据服务器负责存储文件的哪些部分存储在什么地方的信息。
- 多个 I/O 节点上存储了文件的各个部分(PVFS 底层可以使用任何常见的文件系统,例如 ext3 )。
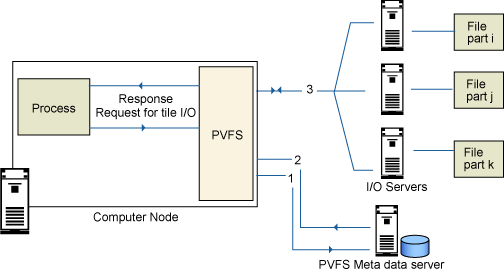
当集群中的计算节点想要访问并行文件系统中的一个文件时,它需要执行以下步骤:
- 像平常一样请求文件,请求被传送到底层的 PVFS 文件系统中。
- PVFS 向元数据服务器发送一个请求(图 4 中的步骤 1、2),这会通知请求节点有关文件在各个 I/O 节点上的位置的信息。
- 使用这些信息,计算节点直接与所有相关的 I/O 节点进行通信,获得整个文件(步骤 3)。
这些步骤对于调用应用程序来说都是透明的;底层对所有 I/O 节点发出请求的复杂性、获取文件的内容等等,都是由 PVFS 处理的。
有关 PVFS 有一件好的事情:不需做任何修改就可以在其上运行普通文件系统的二进制形式 —— 这在并行编程领域多少是个例外。
有关集群最有趣的事情之一是,如果我们有基本的 Linux 安装,并且具备一定的故障排除的技能,只需要很少的努力就可以构建基于 Linux 的集群。让我们来看一下这是如何实现的。
对于我们的集群,要使用 MPICH 和一组普通的 Linux 工作站。为了简单起见,并且重点突出其中的基本原理,我们将构建最小的裸系统,在集群环境中可以使用它来运行并行程序。
本节中给出的 7 个步骤将显示如何构建裸系统。构建健壮的集群以及集群的管理涉及很多工作,我们在本文后面进行介绍。
如果想获得一个真正的集群,至少需要两台 Linux 机器。两个 VMware 映像也可以很好地实现这种功能。(使用 VMware,显然我们并不会期望能获得什么性能优势。实际上,其性能显然会有所下降,因为 CPU 需要进行共享。)请确保这些机器彼此之间可以使用机器名相互 ping 通。否则,就需要在 /etc/hosts 中添加适当的项。
安装 GNU C 编译器和 GNU FORTRAN 编译器。
为所有节点配置 SSH,允许不询问密码就可以执行命令。这样做的目的是能够不需询问密码就可以执行 ssh -n host whoami 这样的命令。SSH 用作不同机器之间的通信方法。(也可以使用 rsh 来实现这种功能。)
ssh-keygen -f /tmp/key -t dsa 可以在文件 key 中生成一个私钥,在文件 key.pub 中生成一个公钥。
如果正在以 root 用户的身份构建集群,并且以 root 用户的身份来运行程序(显然只有在进行实验时才会这样),那么就可以将私钥拷贝到文件 /root/.ssh/identity 中,并将公钥拷贝到集群中所有节点上的 /root/.ssh/authorized_keys 文件中。
为了确保所有的配置都能正常工作,请执行下面的命令:ssh -n hostname 'date',并查看这个命令能否成功执行,而不会出现任何错误。应该对所有节点都执行这种测试,这样就可以确保所有节点上的设置都没有问题。
注意:可能还需要修改防火墙的配置,使其允许节点彼此之间相互进行通信。
接下来,我们将安装 MPICH。从 anl.gov 的 Web 站点(请参阅 参考资料 中的链接)上下载 UNIX 版本的 MPICH。下面是一个简要介绍。
假设您已经将所下载的 mpich.tar.gz 放到了 /tmp 中:
cd /tmp
tar -xvf mpich.tar.gz (假设执行这个命令之后会得到一个 /tmp/mpich-1.2.6 目录)
cd /tmp/mpich-1.2.6
./configure -rsh=ssh —— 这告诉 MPICH 使用 ssh 作为通信机制。
make —— 执行完这个步骤之后,就已经安装好 MPICH 了。
要让 MPICH 知道所有的节点,请编辑文件 /tmp/mpich-1.2.6/util/machines/machines.LINUX,并将所有节点的主机名添加到这个文件中,这样安装的 MPICH 就可以知道所有的节点了。如果以后再添加新的节点,也请修改这个文件。
将目录 /tmp/mpich-1.2.6 拷贝到集群中的所有节点上。
在 examples 中运行几个测试程序:
cd /tmp/mpich-1.2.6/utils/examplesmake cpi/tmp/mpich-1.2.6/bin/mpirun -np 4 cpi—— 告诉 MPICH 在 4 个处理器上运行程序;如果配置中没有 4 个处理器,也不用担心;MPICH 会创建一些进程来补偿物理硬件的缺失。
现在集群已经准备好了!正如我们可以看到的一样,所有的重头戏都可以留给 MPI 实现来完成。正如前面介绍的一样,这是一个裸集群,所需的大部分手工工作只是确保机器之间可以彼此进行通信(我们配置了 ssh,MPICH 是手工拷贝的,等等)。
有一点非常清楚,上面的集群非常难以维护。现在并不能方便地将文件拷贝到每个节点上、在每个要添加的节点上设置 SSH 和 MPI 以及在将节点移出集群时进行适当的修改,等等。
幸运的是,有一些优秀的开放源码软件资源可以帮助我们设置和管理健壮的产品集群。OSCAR 和 Rocks 就是两个这样的软件。我们在创建集群时所执行的大部分操作都可以使用这些程序自动实现。
图 1 是一个简单集群的示意图。
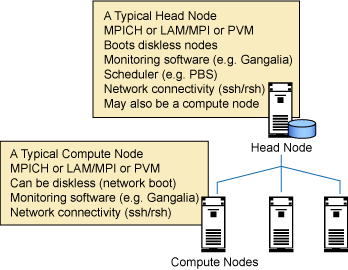
OSCAR 还可以支持使用 PXE(Portable Execution Environment)来自动安装 Linux。OSCAR 还可以帮助我们实现以下功能:
- 在计算节点上自动安装 Linux。
- 配置 DHCP 和 TFTP(对于使用 PXE 安装的 Linux 系统)。大部分新计算机都有一个允许使用 DHCP 服务器来引导机器的 BIOS。BIOS 有一个内建的 DHCP 客户机,它创建一个操作系统映像,并使用 TFTP 将其从 DHCP 服务器传输到要引导的机器上。这个 Linux 映像是由 OSCAR 创建的,DHCP 和 TFTP 的安装和配置都可以由 OSCAR 来处理。
- 配置 SSH。
- 自动设置 NFS。
- 安装并配置 MPI(MPICH 和 LAM/MPI)。
- 安装并配置 PVM (如果希望使用 PVM,而不是 MPI)。
- 配置头节点和计算节点之间的子网。
- 安装调度器(Open PBS 和 Maui),用于多个用户将作业提交到集群上的自动管理。
- 安装 Ganglia,用于性能监视。
- 自动配置,用于添加或删除节点。
现在 OSCAR 可以支持多个版本的 Red Hat Linux;有关其他可以支持的发行版本,请参阅 OSCAR 的 Web 站点。根据在设置时所碰到的错误,可能需要对几个脚本进行修改。
使用 OSCAR 创建 Linux 集群
让我们使用 OSCAR 资源来构建一个功能完备的集群。假设有两个或多个普通的工作站,它们都使用网络连接在一起。将其中的一个节点设置为头节点,其他节点都设置为计算节点。
正如在构建 Linux 集群时所做的一样,我们要详细介绍在头节点上所执行的步骤。OSCAR 可以自动配置其他节点,包括 OS 的安装。(请参阅 OSCAR 安装指南;下面是对安装过程的概念性介绍。)
步骤 1
在头节点上安装 Linux。确保安装 X 服务器。
步骤 2
mkdir /tftpboot, mkdir /tftpboot/rpm。将安装光盘中的所有 RPM 文件拷贝到这个目录中。这些 RPM 用来创建客户机映像。并非所有的 RPM 最终都需要,但是最好让它们自动构建这个映像。
步骤 3
确保已经安装并配置了 MySQL,并且可以从 Perl 中访问 MySQL,因为 OSCAR 将所有的配置信息都保存到了 MySQL 中,并使用 Perl 来访问这些信息。这个步骤通常是可选的,并且 OSCAR 也可以为我们执行这些步骤,但是有时这个步骤会失败,尤其是在一个尚不支持的发行版本上安装时更是如此。
步骤 4
下载 OSCAR 源代码并编译它:
configure
make install
步骤 5
启动 OSCAR 向导。假设我们想要这个集群使用 eth1 来连接集群中的节点,请使用 /opt/oscar/install_cluster eth1。
步骤 6
在这个步骤中,一步步地通过所有的 OSCAR 设置屏幕。确保以正确的顺序执行以下步骤:
- 选择包来定制 OSCAR 的安装。如果不熟悉这些包,可以暂时忽略。
- 安装 OSCAR 包。
- 构建客户机映像。这就是计算节点要使用的映像文件。
- 定义 OSCAR 客户机。这定义的是计算节点。我们需要指定集群中想要使用的节点的个数,以及它们所使用的子网。如果现在不确定一共有多少个节点,可以稍后再来修改。
- 将不同节点的 MAC 地址映射为 IP 地址。对于这个步骤,每个节点都必须在 BIOS 中使用 PXE 网络启动选项来启动。
步骤 7
最后,运行测试。如果一切运行良好,每个测试都应该成功。即使没有任何问题,有时第一次尝试运行时也会有些测试失败。还可以通过执行 /opt/oscar 下面的测试脚本来手工执行这些测试。
如果我们现在希望添加新的节点,可以再次启动 OSCAR 向导并添加节点。OSCAR 会使用 PXE 自动将 Linux OS 安装到这些节点上。
现在我们已经准备好集群环境了,接下来可以运行并行程序了,并且可以根据需要添加或删除新节点,并使用 Ganglia 来监视节点的状态。
管理集群
当我们需要在一个具有大量用户的产品环境中对集群进行管理时,作业调度和监视就变得尤其重要了。
作业调度
MPI 可以在各个节点上启动并停止进程,但是这只能限定于同一个程序。在一个典型的集群上,会有很多用户都要运行自己的程序,我们必须使用调度软件来确保它们可以最优地使用集群。
一个流行的调度系统是 OpenPBS,可以使用 OSCAR 自动安装它。使用这个调度系统,可以在集群上创建作业,并将作业提交到集群上运行。在 OpenPBS 中,还可以创建复杂的作业调度策略。
使用 OpenPBS 还可以查看正在执行的作业、提交作业以及取消作业。它还可以控制某个作业可以使用的 CPU 时间的最大值,这对于系统管理员来说非常有用。
监视
集群管理中的一个重要方面就是监视,尤其是如果集群中有大量的节点就更是如此。此处有几种选择,例如 Ganglia(OSCAR 可以提供)和 Clumon。
Ganglia 有一个基于 Web 的前端界面,可以提供有关 CPU 和内存使用情况的实时监视信息;可以方便地对其进行扩展,使其只监视有关某项内容的信息。例如,使用一些简单的脚本,我们就可以让 Ganglia 汇报 CPU 的温度、风扇转速等等。在接下来的几节中,我们将编写一些并行程序,并在这个集群上运行这些并行程序。
并行算法
并行编程有自己的一些并行算法,它们可以充分利用底层硬件的性能。接下来让我们来了解一下这种算法的信息。让我们假设一个节点要对一组 N 个整数进行求和运算。用普通方法实现这种操作所需要的时间是 O(N)(如果对 100 个整数进行求和需要 1ms,那么对 200 个整数进行求和就需要 2ms,依此类推)。
这个问题看起来很难线性地提高其速度,但是值得注意的是,的确有这样一种方法。让我们来看一个在 4 个节点的集群上执行程序的例子,每个节点的内存中都有一个整数,程序的目的是对这 4 个整数求和。
考虑下面的步骤:
- 节点 2 将自己的整数发送给节点 1,节点 4 将自己的整数发送给节点 3。现在节点 1 和节点 3 都有两个整数了。
- 这些整数在这两个节点上分别进行求和。
- 节点 3 将它的部分和发送给节点 1。现在节点 1 有两个部分和了。
- 节点 1 对这些部分和进行求和,从而得出最终的总和。
正如我们可以看到的一样,如果最初有 2N 个数字,这种方法在 ~N 个步骤中就可以实现求和运算。因此算法的复杂度是 O(log2N),这相对于前面的 O(N) 来讲是一个极大的改进。(如果对 128 个数字进行求和需要 1ms,那么使用这种方法对 256 个数字进行求和就只需要 (8/7) ~ 1.2ms。在前面的方法中,这需要 2ms。)
这种方法在每个步骤中都可以释放一半的计算节点。这种算法通常就称为递归二分和倍增(recursive halving and doubling)法,它就是在 MPI 中 reduce 函数调用的类背后所采用的机制,稍后我们就要讨论。
在并行编程中,有很多为实际问题所开发出的并行算法。
使用 MPI 进行并行编程来实现矩阵与向量的乘法
现在我们已经了解了并行编程平台的基础知识,并且准备好了一个集群,接下来就要编写一个可以很好地利用这个集群的程序。我们并不编写传统的 “hello world”,而是直接跳到一个真实的例子上,并编写基于 MPI 的程序来实现矩阵与向量的乘法。
我们将使用在 并行算法 一节中介绍的算法来很好地解决这个问题。假设有一个 4X4 的矩阵,我们希望将其与另外一个 4X1 的向量进行乘法操作。我们将对矩阵乘法的标准技术稍微进行一下修改,这样就可以使用前面介绍的算法了。
我们并不对第一行与第一列进行乘法操作,而是将第一列中的所有元素与向量中的第一个元素相乘,第二列的元素与向量中的第二个元素相乘,依此类推。采用这种方法,就可以得到一个新的 4X4 矩阵。然后,将每一行中的所有 4 个元素相加,得到一个 4X1 的矩阵,这就是最后的结果。
MPI API 有多个函数可以直接解决这个问题,如清单 1 所示。
清单 1. 使用 MPI 执行矩阵乘法
/*To compile: 'mpicc -g -o matrix matrix.c'To run: 'mpirun -np 4 matrix'"-np 4" specifies the number of processors.*/#include <stdio.h>#include <mpi.h>#define SIZE 4int main(int argc, char **argv) { int j; int rank, size, root; float X[SIZE]; float X1[SIZE]; float Y1[SIZE]; float Y[SIZE][SIZE]; float Z[SIZE]; float z; root = 0; /* Initialize MPI. */ MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size);/* Initialize X and Y on root node. Note the row/col alignment. |
性能测试
集群已经构建好,可以执行程序了,接下来需要了解这些程序的执行速度到底有多快。通常我们都认为是处理器的频率决定了性能的高低。对于特定的范围来说,这个结论是正确的;但是在不同供应商的处理器或相同供应商提供的不同处理器系列之间进行比较,没什么意义,因为不同的处理器在给定的时钟周期内所执行的任务量是不同的。在 第 1 部分 中对向量和标量处理器进行比较时,这尤其明显。
对性能进行比较的一种更加自然的方法是运行标准测试。随着时间的推移,有一个非常出名的 LINPACK 基准测试已经成为比较性能的标准。它是由 Jack Dongarra 在十年之前开发的,现在仍在由 top500.org 使用(请参阅 参考资料 中的链接)。
这个测试要解包含 N 个线性方程的密集方程组,其中浮点操作的个数是已知的(是 N^3 级别)。这个测试非常适合用来测试那些要运行科学应用程序和模拟的计算机,因为它们都要在某些步骤上试图对线性方程进行求解。
测试的标准单位是每秒执行的浮点操作数量,即 flop 数(在这种情况中,flop 或者是一个 64 位的加法操作,或者是一个 64 位的乘法操作)。这个测试要测量的内容如下:
- Rpeak,flop 的理论峰值。在 2005 年 6 月的报告中,IBM Blue Gene/L 的时钟峰值为 183.5 tflop(万亿 flop)。
- Nmax,得出最高 flop 时所使用的矩阵大小 N。对于 Blue Gene 来说,这个值是 1277951。
- Rmax,Nmax 所达到的最大 flop。对于 Blue Gene 来说,这个值是 136.8 tflop。
为了更好地理解这些数字,请考虑下面这个事实:IBM BlueGene/L 在 1 秒之内可以完成的操作在一台家用计算机上需要执行 5 天。
现在让我们来讨论一下如何对 Linux 集群进行基准测试。除了 LINPACK 之外,其他基准测试还有 HPC Challenge Benchmark 和 NAS benchmark。
对 Linux 集群进行基准测试
要在 Linux 集群上运行 LINPACK 基准测试,我们需要获得一个并行版本的 LINPACK,并对这个集群配置 LINPACK。我们将一步步地介绍整个过程。
警告:下面使用了普通的线性代数库;使用它只是作为一个参考。对于一个真正的测试来说,要使用已经针对自己的环境优化过的库。
步骤 1
从 netlib.org 下载 hpl.tgz,这是 LINPACK 基准测试的并行(MPI)版本(请参阅 参考资料 中的链接)。
步骤 2
从 netlib.org 下载 blas_linux.tgz,这是预先编译好的 BLAS(Basic Linear Algebra Subprograms)。为了简单起见,可以使用一个为 Linux 准备的预先编译好的 BLAS 参考实现,但是为了能够得到更好的结果,应该使用硬件供应商所提供的 BLAS,或者使用开放源码的 ATLAS 项目进行自动优化。
步骤 3
mkdir /home/linpack; cd /home/linpack(我们要将所有的东西都安装到 /home 中)。
步骤 4
解压并展开 blas_linux.tgz,这样应该会得到一个名为 blas_linux.a 的文件。如果看到了这个文件,就可以忽略所看到的错误。
步骤 5
解压并展开 hpl.tgz,这样应该会得到一个目录 hpl。
步骤 6
将所有的配置文件(例如 Make.Linux_PII_FBLAS)从 hpl/setup 拷贝到 hpl 目录中,并将 hpl 中的拷贝重命名为 Make.LinuxGeneric。
步骤 7
编辑文件 Make.LinuxGeneric 中下面的内容,并修改为适合您的环境的值:
TOPdir = /home/linpack/hpl
MPdir = /tmp/mpich-1.2.6
LAlib = /home/linpack/blas_linux.a
CC = /tmp/mpich-1.2.6/bin/mpicc
LINKER = /tmp/mpich-1.2.6/bin/mpif77
这 5 个地方指明了步骤 1 中 LINPACK 的顶级目录、MPICH 安装的顶级目录以及步骤 2 中 BLAS 参考实现的位置。
步骤 8
现在编译 HPL:
make arch=LinuxGeneric
如果没有错误,就会得到两个文件 xhpl 和 HPL.dat,它们都在 /home/linpack/hpl/bin/LinuxGeneric 目录中。
步骤 9
在集群上运行 LINPACK 基准测试之前,将整个 /home/linpack 目录拷贝到集群中的所有机器上。(如果使用 OSCAR 创建的集群并配置了 NFS 共享,就可以忽略这个步骤。)
现在 cd 到在步骤 8 中所创建的可执行程序所在的目录,并运行一些测试(例如 /tmp/mpich-1.2.6/bin/mpicc -np 4 xhpl)。应该会看到使用 GFLOP 表示的执行结果。
注:上面的步骤会基于矩阵大小的缺省设置来运行一些标准测试。使用文件 HPL.dat 来对测试进行调优。有关调优的详细信息可以在文件 /home/linpack/hpl/TUNING 中找到。
IBM Blue Gene/L
现在我们已经构建好了集群,接下来快速介绍一下 Blue Gene/L,这是一台基于集群的非常好的超级计算机。Blue Gene/L 是一项大型的工程壮举,对其进行详细介绍显然已经超出了本文的范围。现在我们只是简单介绍一下表面的东西。
三年前,地球模拟器(Earth Simulator)(向量处理器)成为世界上最快的计算机,很多人都预测集群作为一种超级计算机平台已经走向了死亡,向量处理器已经复苏了;这个结论下得太早了。Blue Gene/L 在标准的 LINPACK 基准测试中已经彻底击败了地球模拟器。
Blue Gene/L 并不是使用常用的工作站来构建的,但是它依然使用本系列文章中所讨论的标准集群技术。它使用了一个源自于本文中使用的 MPICH 的 MPI 实现。它还可以运行 700MHz 的标准 32 位 PowerPC® CPU(不过这些是基于片上系统或 SoC 技术的),这比该系列中的其他机器更能极大地降低对制冷和电源的需求。
Blue Gene/L 是一个非常大的机器,有 65,536 个计算节点(每个节点都运行一个定制的操作系统),还有 1,024 个专用的 I/O 节点(运行 Linux 内核)。使用如此多的节点,网络就尤其重要了,Blue Gene/L 可以使用 5 种不同类型的网络,每种网络都为一个特定的目的进行了优化。
| 自由广告区 |
| 分类导航 |
| 邮件新闻资讯: IT业界 | 邮件服务器 | 邮件趣闻 | 移动电邮 电子邮箱 | 反垃圾邮件|邮件客户端|网络安全 行业数据 | 邮件人物 | 网站公告 | 行业法规 网络技术: 邮件原理 | 网络协议 | 网络管理 | 传输介质 线路接入 | 路由接口 | 邮件存储 | 华为3Com CISCO技术 | 网络与服务器硬件 操作系统: Windows 9X | Linux&Uinx | Windows NT Windows Vista | FreeBSD | 其它操作系统 邮件服务器: 程序与开发 | Exchange | Qmail | Postfix Sendmail | MDaemon | Domino | Foxmail KerioMail | JavaMail | Winwebmail |James Merak&VisNetic | CMailServer | WinMail 金笛邮件系统 | 其它 | 反垃圾邮件: 综述| 客户端反垃圾邮件|服务器端反垃圾邮件 邮件客户端软件: Outlook | Foxmail | DreamMail| KooMail The bat | 雷鸟 | Eudora |Becky! |Pegasus IncrediMail |其它 电子邮箱: 个人邮箱 | 企业邮箱 |Gmail 移动电子邮件:服务器 | 客户端 | 技术前沿 邮件网络安全: 软件漏洞 | 安全知识 | 病毒公告 |防火墙 攻防技术 | 病毒查杀| ISA | 数字签名 邮件营销: Email营销 | 网络营销 | 营销技巧 |营销案例 邮件人才:招聘 | 职场 | 培训 | 指南 | 职场 解决方案: 邮件系统|反垃圾邮件 |安全 |移动电邮 |招标 产品评测: 邮件系统 |反垃圾邮件 |邮箱 |安全 |客户端 |